实证类论文该怎么写?—写给每一个被Stata折磨过的研究生

每一个做实证分析的人,都经历过同样的夜晚:
变量不显著、数据跑不动、模型出错、导师催进度。
你以为你在做计量,其实你是在修炼“科研耐心”。
这篇推文,不讲术语、不摆框架,只想带你走一遍——
一篇实证论文,从0到1的真实过程。
实证论文最难的,不是模型,而是开始。
刚开题的时候,你会陷入无尽的纠结——
到底该研究什么?
选题要多新才行?
数据能下到吗?
很多同学一上来就冲着方法去:“我要做DID”“我要上GMM”,
可冷静一下,你得先知道你要研究的问题是什么。
最好是“兴趣+导师方向”的结合,这样才能坚持下去。
我那时候就是从一个关键词开始的,比如“数字化转型”“绿色创新”“资本结构”。
在知网上搜几十篇文章,一篇篇啃。前几篇根本看不懂,看到模型部分就想关电脑。
但咬牙看完几篇后,你会突然发现:
原来别人文章里变量是这么量化的,数据是这么来的,机制是这么讲的。
那一刻,你算是正式入门了。
接下来,就是炼狱:找数据。
我那时候用的Wind和CSMAR。
Wind界面好看,但只能下一个时间点;
CSMAR能下面板数据,但表格多、匹配难。
如果你做的是跨年面板数据,CSMAR更合适。
别怕下载多,怕的是漏。
变量漏一列,你就要返工三天。
然后你会发现更崩溃的部分:清洗数据。
删金融企业、删空白、删乱码、删异常值,报表类型还要区分母公司和总公司。
匹配时用Vlookup,日期格式要改,中文要换成英文。
Stata对中文零容忍,不认百分号、不认斜杠、不认汉字。
我第一次导入数据,整屏全红,直接怀疑人生。
好不容易数据干净了,终于能跑模型。
结果第一次跑完回归,P值:0.9。
我愣了五分钟。
显著性没出来怎么办?
你会经历所有人都经历过的那几步:
缩尾(winsor2),分组回归,改变量定义,删时间段,换算法。
显著性虽然能调出来,但那种过程,
就像你在和Stata谈一场不平等的恋爱。
导师一句“这结果不太稳健”,你又要重来。
如果需要论文指导,可联系网站客服!
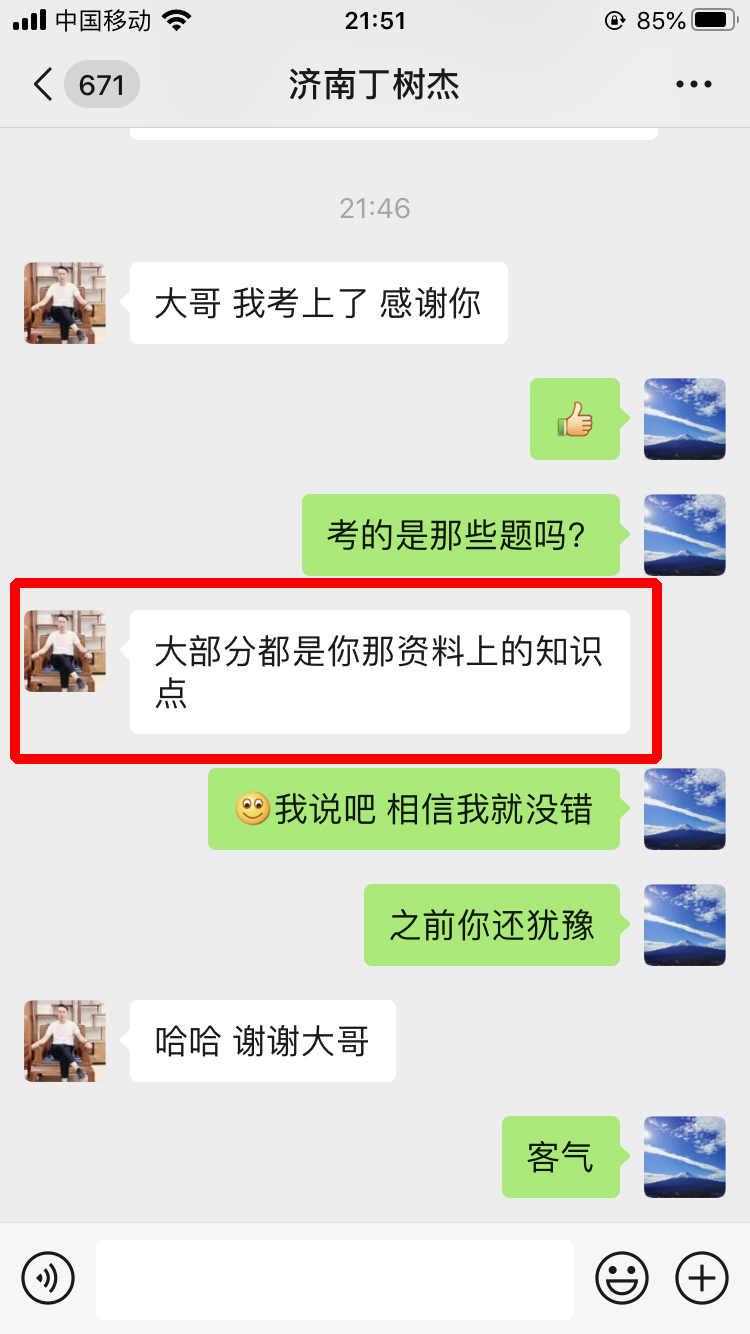
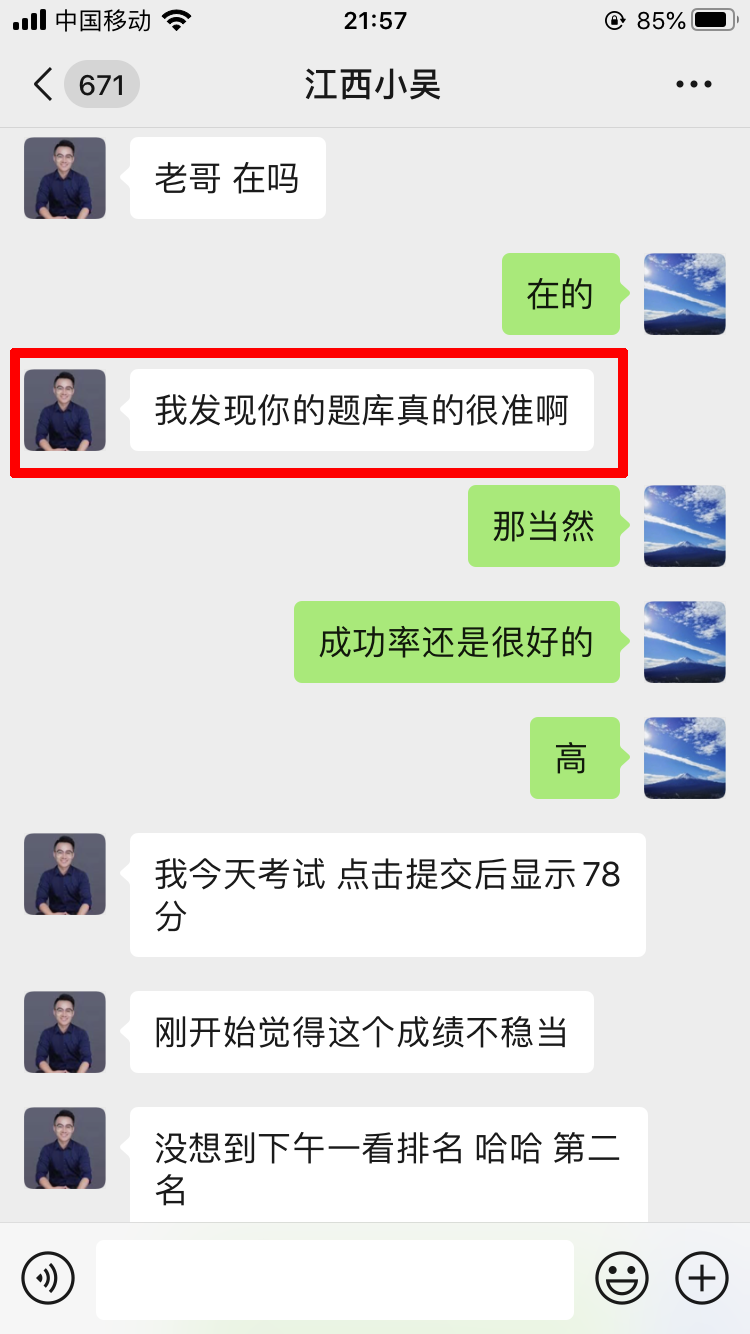
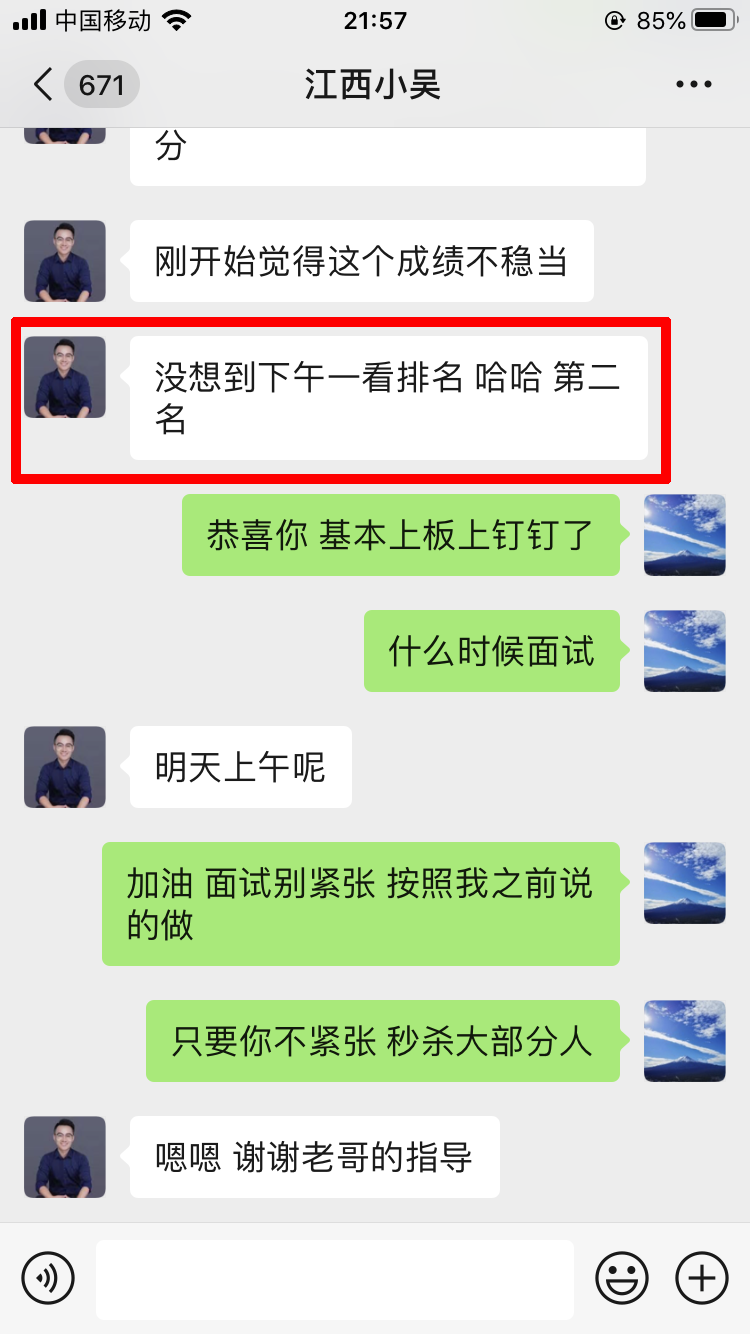
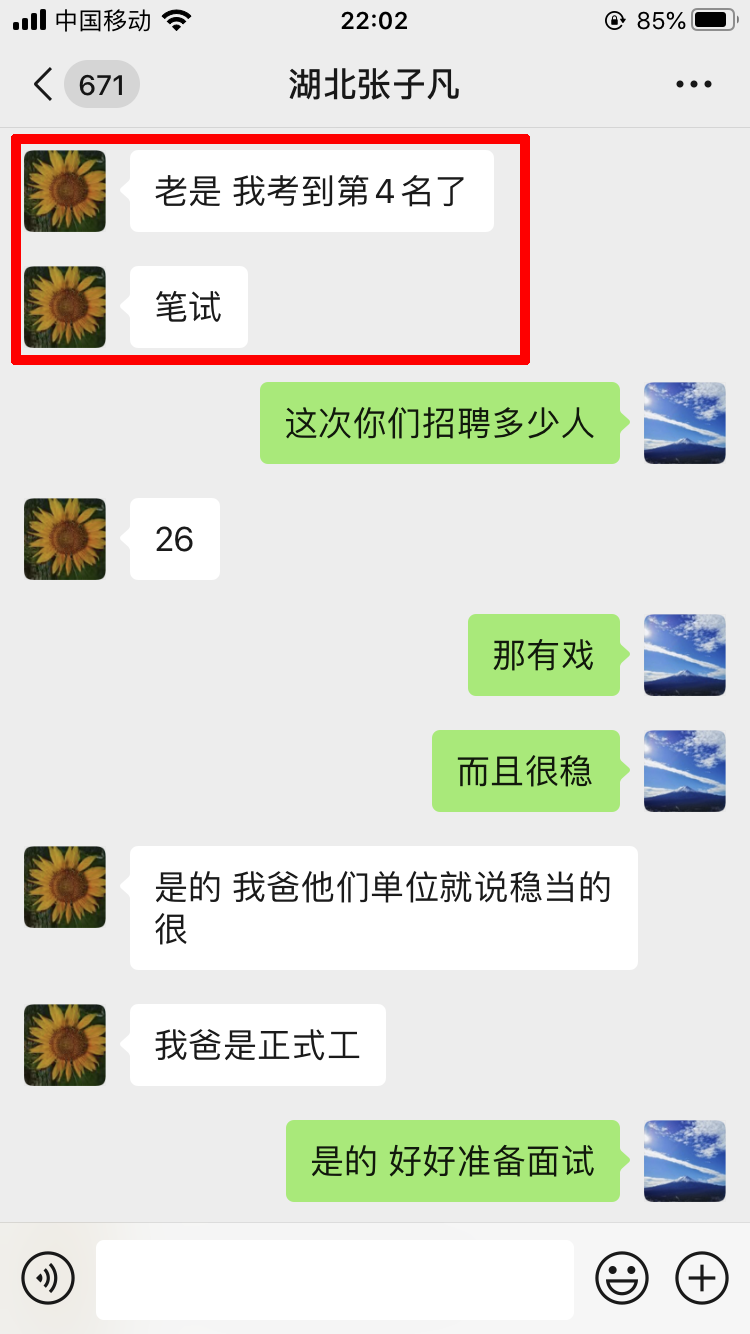
学员评价
- 上一篇:学位论文的格式和排版(A)
- 下一篇:没有了
